MS SQL - Database & Backups
Yes. You can also place the databases used by Window Book, Inc. products on an existing SQL Server instance that you already manage.
You can use spanned logs with databases wbdb and wbdbcla, but DAT-MAIL does not support spanned logs for the MD*** (Mail.dat) databases, which are using Simple recovery mode.
No
We provide a program that will start standard Microsoft SQL Server backups using standard MSSQL facilities, but there is more to managing a SQL instance than simply running backups. Your IT shop should know that backups should be managed and archived as necessary.
We are working on a framework of procedures for our customers who do not have MS SQL specialists on staff so that the existing IT team can start with those procedures and adapt them to their needs.
No. Refer to Supported SQL Server Versions for more information.
Some virtualization platforms allow you to virtualize a physical machine into a VM.
That aside, we would suggest converting to MS SQL first unless the existing machine is resource-constrained for RAM or CPU. If the current computer is resource-constrained, we recommend migrating to a newer computer with more resources, then upgrading to MSSQL.
Each computer can only have one SQL instance with a given name, whether that name is "SQLExpress" or "GreenBayPackers."
If this failure occurs, you'll need to use a SQL Server installer to install a SQL Server instance with a different instance name (the instance name is your choice). Our installers cannot change that name.
After installing a new SQL Server instance, our installer asks if you want to install SQL Server or use an existing SQL Server. Select that you want to use an existing SQL Server instance and use the drop-down list to select that instance. If the name does not drop down in the installer, it means that you are not running the SQL Server Browser service. You can either type the name of the SQL instance or start the SQL Server browser service and then click back and next in the installer so it will re-query the system for available databases.
Window Book uses separate databases for each Mail.dat. In addition, we currently use two databases, wbdb for .Net functionality and wbdbcla for other functionality. Using two databases allows for 10 GB in each database, plus up to 10 GB in each Mail.dat database. Despite this and efforts to purge old data to reclaim space, it is unlikely that high-volume mailers will be able to avoid licensing Microsoft SQL Server Standard Edition permanently.
If a database reaches the 10 GB limit, SQL Server will prevent further additions or updates to the database. Deletes are usually possible, but deleting a few records or jobs will not prove a good long-term solution. At that point, you will need to license SQL Server Standard Edition.
You can backup your MSSQL databases by database name. You should backup wbdb and wbdbcla as often as necessary for your needs. While DAT-MAIL handles the MD*** database backups, it would be prudent to backup the \wb folder, which contains the MD*** database backups by default.
At sites where the DAT-MAIL server and the SQL Server used by DAT-MAIL are on the same machine, the default location for these backups is C:\WB\MDV\DATA\DMMailDatSQLbackups\. That is assuming DAT-MAIL is on the C drive in \wb\.
However, on systems where SQL Server is not on the DAT-MAIL server, this folder must be located elsewhere. You can determine this location using this query:
SQL Query
use wbdbcla
go
select KeyValue from DynData
where KeyDomain = 'DatMail' and KeyDomainID = 'MSSQL' and KeySubDomain = 'Settings'
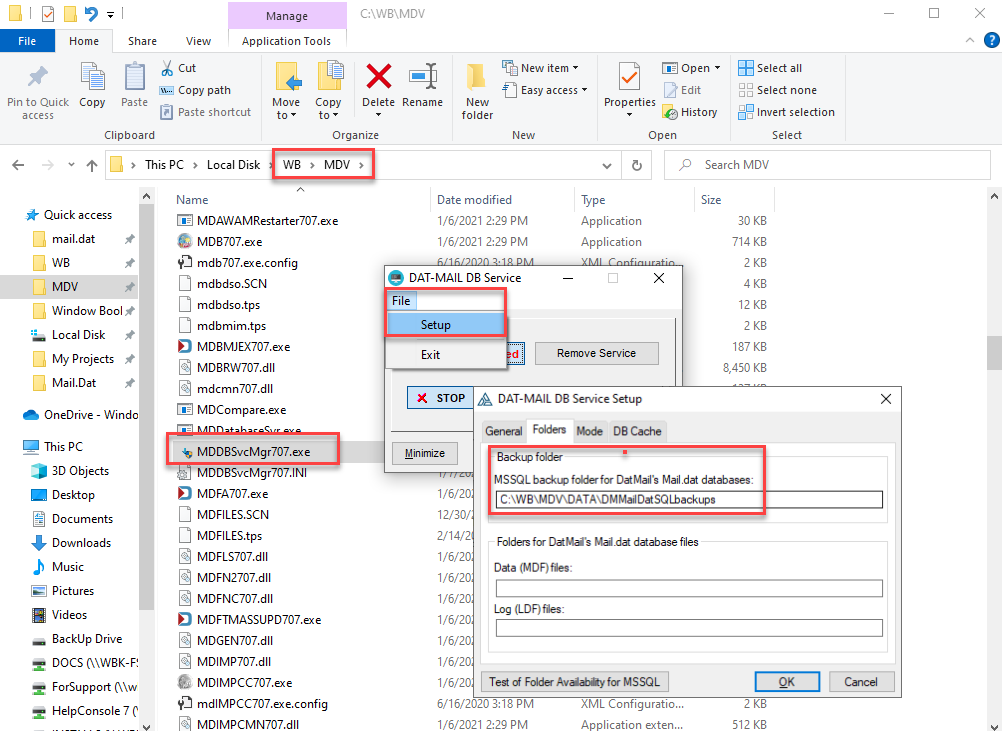
and KeySubDomainID = 'Backup' and KeyName = 'Path'Another way to find this information is in this application's Setup executable (MDDBSvcMgr707.exe). The executable file for the application is in: '...WB\MDV'. Launch the application, select the File menu, then Setup. The DAT-MAIL DB Service Setup screen will display. Next, select the Folders tab, and the 'Backup folder location will show.
In most databases (including our wbdb and wbdbcla databases), data from many different work efforts of the same type intermingles on tables. For example, in a postage accounting table, there will be records related to multiple jobs. For traditional transactional data models, this is quite normal. However, the Mail.dat file format is, in fact, a set of related files that describe a single mailing job. In most cases, it is delivered by the presort software as a ZIP.
The Mail.dat file is more like a complex object, yet changes to the file are of the nature they cannot partially complete. As such, there is never a need to roll forward changes to a Mail.dat database backup. The LDF (SQL log file) in Simple mode is simply for transaction rollback after a failure. There is never a need to roll forward from a full backup of a Mail.dat database. The upside of this is that the LDF files for the Mail.dat databases should only grow as necessary to support transaction rollback.
Except MD*** databases needing to be in Simple mode as discussed above, we suggest you use Full recovery mode for the wbdb and wbdbcla databases.
Microsoft's comments on when it is acceptable not to use Full recovery mode.
When you use the Simple recovery model, you are saying that:
-
Your data is not critical and is easy to recreate
-
The database is for test or development
-
Losing any or all transactions since the last backup is not a problem
Unlike the MD*** databases, none of the circumstances noted above by Microsoft could be considered valid for wbdb or wbdbcla. Please use Full recovery mode for wbdb and wbdbcla. Please backup your databases and transaction logs.
Yes, with one restriction:
Backup software cannot take exclusive control of databases wbdb, wbdbcla, or those named MD***. Our products contain significant automated, lights-out functionality. Locking these databases can cause your mailing/shipping team's in-flight production work to fail due to the inability to access these databases.
Dell Rapid Recovery is one of the backup tools that takes exclusive control of the databases. We are not aware of the ability to configure it to avoid locking databases. Dell can help with that. Regardless of the tool you are using, it cannot take exclusive control of the database without negatively impacting your mail production.
A better question is how much of the work that your staff performed in the last hour(s), day(s) or week(s) are you willing to have them redo/recreate?
For example, if you backup weekly and run transaction log backups every 24 hours and then you have a catastrophic data loss that requires you to restore your SQL data, the process will look like this:
You restore from the last weekly backup.
Rolling log transactions forward for as many as seven days. While that is happening, no other work on these databases can be taking place.
Once this restore process is complete, your staff will have to redo any work occurring after the last transaction log backup.
Considering the shops we interact with, we suggest backing up your database daily and taking transaction log backups at least every 4 hours - more often if you can. That means that you will be restoring a full backup and rolling forward no more than 4 hours of work and then redoing no more than 4 hours of work - the work since the last transaction log backup. Busier, larger, higher volume sites may wish to run transaction logs more frequently. Rework is not fun, is not cheap, and always comes when everyone wants the work done as fast as possible.
How is this different from the days of using non-SQL solutions? Non-SQL solutions have no roll-forward capability. You'd have to redo all the work since the last full backup.
We don't recommend a specific tool for this, but we believe these tools have value.
However, you must exempt the MD*** databases from these tools, and you should be careful to test these tools with your systems. Some of them default to setting the databases into a single-use mode, which can break in-flight processes, prevent anyone from getting into our products, and similar. A real-time backup tool that requires single-user mode is not a good choice in our view.
The Windows login used to run a Window Book product installer must be a Windows administrator. It must have SQL Server Administrator access (sysadmin server role) on the SQL instance with Window Book databases (wbdb, wbdbcla, and the MD*** databases).
We can provide you with a zip of the scripts.
You can tell our installers to skip ALL SQL functionality but this requires that you run the SQL scripts manually and in the proper order prior to using a newly installed version of our products. This can be quite a tedious task as there are quite a few scripts (well over 100, and growing with every release of our products).
There are a number of reasons:
-
The unique data model (actually an object model) necessary to handle the DTAC Mail.dat file format.
-
Workflow of using Mail.dat files.
-
Performance.
-
Cost.
There's a lot to cover here, so a refresh on the coffee might be appropriate.
Unique Mail.dat data model
In most databases (including our wbdb and wbdbcla databases), the same data complete many different work efforts of the same type. For example, in a postage accounting table, there will be records related to multiple jobs. For traditional transactional data models, this is quite normal. However, the Mail.dat file format is, in fact, a set of files rather than an individual file. In most cases, it is delivered by the presort software as a ZIP.
The Mail.dat file is more like a complex object. The files within the Mail.dat zip file represent all the pieces, entry points, containers, barcodes, and the relationships between these entities (and others) in the job. While the Mail.dat is multiple files, when revising it, it is like one entity. It is a "job." When it is open, the data from no other jobs are available (there are exceptions like split and merge, but bear with us). When edits occur on a Mail.dat database (a job), they are atomic for the job, not for the specific file within the job. Either they succeed as a whole, or all files require restoration to their previous state.
In many cases, the same Mail.dat is imported into DAT-MAIL repeatedly (sometimes 100s of times) for QA, validation, and other reasons. Users demand the same job name for each import, yet the jobs are independent. One of the reasons why we store Mail.dats (a Mail.dat documented job) in its database, isolated from all others, is because of the object-oriented nature of the database. Likewise, there is the need to perform operations on the job as a whole - without affecting any other job, even jobs created from the same file.
Workflow and Performance
We could address these two topics separately, but they are so intertwined.
Rather than store all of this Mail.dat data in a single set of tables on one database, we store them on individual databases dedicated to the Mail.dat file (that job).
A good example of selecting the many-database model is the requirement to perform Mail.dat job splits and merges - a routine process for many of our Clients. The I/O required to do this on a shared database/shared table model could be massive in splits and merges. In a traditional shared data model, every user impacts performance. We have Clients who routinely (at least once a month) split or merge 20 million piece jobs. That means deleting, updating, or inserting a minimum of 20 million records and updating foreign keys across many of them. Depending on the situation, deleting (or updating) and inserting this volume of records would be required to perform one split or merge. These operations on a shared database would also significantly impact log file management, log sizes, and overall performance.
Log management is significantly reduced in the database-per-job (Mail.dat) model because we can afford to set the MD*** databases to Simple recovery. We could never get away with that in a shared database, especially one that contains every piece of information about every Mail.dat job in process or processed in the last 13 months (the typical USPS expectation for retention).
Mail.dat processing is single-user oriented. Our products do not allow more than one user to update a Mail.dat at a time. The data model discussion briefly touched on that. When a user opens a job, its database is attached and opened. When a user closes the job, the database is closed and detached. When no one or no automated task is actively processing the job, there is no reason for the Mail.dat's data to be available. The statement and accounting information related to a Mail.dat is not in the Mail.dat database. Each Mail.dat database (MD***) mimics the file set in the Mail.dat spec; thus, the MD*** database is the SQL equivalent of the Mail.dat zip file.
There are situations where mailers need to merge multiple Mail.dat files or split a single Mail.dat job into many Mail.dats. It is not unusual to hear of a mailer merging 700-1000 Mail.dat jobs into one. Or a mailer, splitting a single large job out by entry point and mailing date, thus creating hundreds of jobs (and thus, Mail.dat files) from a single Mail.dat.
Once a Mail.dat job is complete, we recommend deleting it from DAT-MAIL and keeping the PostalOne! release files for 13 months. The deletion process removes the job from the database. For the database-per-Mail.dat model, this means backup and drop versus millions of I/O routines running in a shared database environment - all to take a job out of visibility. In a shop with Standard Edition, perhaps this data could be marked as archived with a single SQL command, but that still requires millions of I/Os. Log traffic and performance impact - and it leaves one more job on the database. It would not be long before reaching the 10GB maximum in a shop with the Express Edition. This size limitation forces a mailer to perform a purge process, resulting in more I/O, log traffic, and complexity. While we do not recommend archiving jobs, some mailers want to archive jobs to unarchive later. When restoring jobs, the same considerations apply. In a database-per-Mail.dat shop, restoring one MD*** database will impact other users. Again, in a shared data model, millions of I/Os must take place. Once the research is complete, the job is archived, meaning a backup and drop, or millions of more I/Os, depending on the data model.
Sometimes, users make Mail.dat changes, and then it is decided to abandon those changes. In DM, we call this "restore to original, " which would require the restoration of millions of records in a shared database. In a database-per-Mail.dat model, running a standard SQL restore of that database from the original backup DAT-MAIL makes of the initially imported Mail.dat. Allowing mail and transportation departments to control this "restore to original" process is why DAT-MAIL needs to manage MD*** backups rather than a typical automated backup system. Given the deadline pressure they are always under, they cannot afford to file a traditional IT department ticket, wait for a restore (or 40 million I/Os) and then resume their work with that job.
You may not be aware of the record counts involved with these processes. They go as high as 8 or 9 billion mail pieces per year. Even the "small" mailers are mailing several hundred thousand pieces a month. Each piece represents a fair bit of I/O when you consider the workflow from initial import through exporting a ready-to-pay Mail.dat and then deleting or archiving a completed job. It adds up quickly due to the nature of the Mail.dat file format.
Cost
First and foremost, our goal is to avoid the requirement that DAT-MAIL users license SQL Server Standard Edition. We know that our larger or higher-volume users will need Standard Edition, and many will have Standard Edition for other reasons. But the rest of our users would face an extra expense ranging between $3000 and $30,000, depending on their configuration. In most cases, the cost of SQL would be higher (or much higher) than the mailer's investment in DAT-MAIL. We feel that it is not in our Clients' best interest. The database-per-Mail.dat avoids sharing one database with every job, thus avoiding the 10GB limit for all but our largest Clients.
Yes, it is.
Keeping in mind the Mail.dat data model discussion above, all the MD*** databases are detached to reduce SQL overhead significantly and thus, improve performance.
A fair number of our users have 3000-9000 (or more) active Mail.dat jobs in their system due to a combination of their job volume and the lifespan of a job (60-90 days is not unusual). When these many databases are attached, SQL Server is constantly monitoring them. There is some overhead to this, and overhead times 3000 to 9000 adds up fast and substantially impact SQL performance if left as is. MD*** databases are not in use when the Mail.dat job is not open in DAT-MAIL. As such, there is no reason to leave them attached. Detaching all the MD*** databases greatly reduces the RAM and CPU required for SQL Server's needs, even if the SQL instance is doing no other work.
Our products do not differentiate between "regular" and "power" users as far as SQL security is concerned, however some of our products do require the ability to create and drop databases.
DAT-MAIL end users must have the instance-level db_creator role because some features require the use of temporarily created (but not "temporary") SQL databases. In addition, end-users require db_datareader and db_datawriter. If end-users use our backup utility (wbBackup) to backup SQL databases, they must have the db_backupoperator role. The DAT-MAIL Database Service initiates backups in DAT-MAIL, so assign db_backupoperator role to the service's login. The assignment of work to this central service allows you to avoid giving extensive rights to end-users.
The Windows user name used to run the DAT-MAIL database service, which runs as a Windows Service (MDDatabaseServer.exe - service name "WindowBook Dat-Mail database service") requires the instance level db_creator role. It should be a member of the Windows administrator group as it is a secure means of handling database creation and drops for individual Mail.dat MSSQL tables. The service's Windows login should also have db_ddladmin for wbdbcla and wbdb.
Some of this goes back to the data model question above since the unusual Mail.dat data model (which Window Book has no control over) is the reason for using separate databases. However, the ultimate root of this requirement is that SQL Server has some unusual behavior related to permissions when end-user applications request a detach or attach a SQL database. The net result is that for the service to attach and detach, it needs administrator rights.
You can read about the details of this behavior at the following links:
-
https://connect.microsoft.com/SQLServer/feedback/details/539703/access-denied-attaching-a-database-when-permissions-are-inherited (bug report where Microsoft indicates this behavior is by design)
-
https://sqlsunday.com/2016/05/11/detaching-a-database-alters-the-file-permissions/
Other links on the topic:
No.
If your users need to be added to the administrators' group to avoid error messages or other issues, please contact our Support Team.
No.
Please contact our Support Team to investigate any appearance that this is necessary.
We expect that your data will remain available as long as the instance name in \Public Documents\Windowbook\wbdb.xml can be accessed.
If, for some reason, the instance name changes as part of a cluster failover and no redirection is done to a recovery instance, our products will not know what instance to use for your mailing data. This can easily be corrected by editing wbdb.xml to refer to the recovery instance.
No.
Our products exclusively use Windows Authentication. You can use a mixed-mode instance, but our products will still use Windows Authentication.
If you are running a server OS, that server OS requires SQL Server to be installed separately. This is a limitation of the server OS, usually due to security considerations.
Once the SQL install is complete, rerun the Window Book installer. When the Window Book installer asks whether you want to use an existing SQL instance or install a new one, tell it to use the SQL instance you just finished installing.
SQL Server 2016, 2017, and 2019 installs no longer include SQL Server Management Studio (SSMS), which you will need. Use this link to download SQL Server Management Studio (SSMS) for SQL Server 2016, 2017, and 2019.
We use SQL_Latin1_General_CP1_CI_AS for (among other reasons) the performance reasons discussed here:
See also